
Alright friends, we're taking a bit of a different approach with todays article. I'm not going to explain to you any fancy design patterns nor am I going to show you how to test or refactor code.
We're going to talk about designing and building a Blazor web app from the ground up. From idea to fully working product deployed out on the Interwebz.
Sound interesting? Let's rock and roll.
NOTE: exclusive newsletter articles should be ad-free aside from affiliate ads. You should not be seeing any Google ads. If you are, please send a screenshot to [email protected] and I'll fix it. Thank you for your support!
Reminder that you can find me on these platforms:
Background
So... Why?
There are plenty of options for us to go build example projects to gain experience -- but I wanted to take the time to build something I want to use. One of the things that I try to impart on my audience is that I have experience building products that ship. And there's a big difference between trying to write code just to write code, and building products that you ship to customers and iterate on.
I want to be able to highlight the thought process that I put into building a real solution that I want to use. While I could apply this mentality to any of the example projects we might go tackle together, I wanted this to be real so that I don't have to make it an artificial situation.
I'm also busy as hell so I want to make sure if I spend the time building an entire application with all of you over a period of time that I can use it.
The Problem Statement
That brings me to my next point... I'm busy. Super busy most of the time. Writing articles, creating videos, and trying to be active on social media take a lot out of me on top of my 9-5 job. I'm also prepping for a bodybuilding show so I'll be doing more and more cardio which means more and more time not doing other things.
But getting motivation to stay consistent with content creation is hard for me. It's not like I'm raking in the big bucks from posting across 15 channels daily with multiple pieces of content... It loses me money. But I'm in this for the long haul.
As a result, I'm interested in growth of my online presence as I continue to be consistent across these platforms. But there's no one tool that has a historical trend of all of the platforms I like to use.
So we're going to build that. And it's going to be awesome.
Kicking Things Off
Before we dive into building or designing anything, I need to mention this: This is going to be something that takes several weeks for us to put together. I'll be taking to YouTube with the design and coding videos, but I'll update on the newsletter as we make progress building things out.
If the video content is something that gets scheduled out further than the newsletter, I'll just leave them as unlisted on YouTube. You can check them out that way until their published, so you won't be held up by my public publishing schedule.
The point is that we're not building this all at once and I want you to come along for the journey.
Where The HECK Do We Start?
Whose Problem Are We Solving?
I want to discuss the high level view of the system we're building, but first, I think we need to start with who we're building this for.
Me.
But to be a little bit more generic, we want to create this application for someone that's interested in seeing the growth of their social presence over time all in one place. We're going to have to support a handful of platforms for metrics and at least initially, I don't care if I need to run this off my computer to see it working -- no fancy cloud infrastructure required (to start). I also want to make sure I can extend the system when I venture off into new platforms.
The reason we start like this is we want to make sure we're solving real challenges for real people. This is how we deliver value to customers with software. It's the same reason the awesome calculator you built as a side project likely didn't revolutionize anyone's life... and that's okay! Because it was for learning. But when we start working for companies and building software with customers, we need to be focused on delivering value to customers.
What Comes Next?
For me, I like to ideate about how I'm going to solve the problem. I try to leave out specific technology at this point in time because it's too early for that (unless there's a technology unique enough that leveraging it is in fact the value add).
In this particular case, we're going to want to end up with a hosted web app. I'm creating that requirement because I'm playing the customer here too. But could we use React? Blazor? Something else? Ultimately, that doesn't matter right now and we should usually keep our options open so we can evaluate technology later. I *did* cheat a little bit and pick Blazor for us because the newsletter survey results had people asking for more Blazor content.
Do We Choose Tech Yet?
Do we need a database? Which database? Where will we host it? Which libraries will we use? The details of these are mostly irrelevant. So try to calm the chatter in your mind when thinking about this stuff.
From my perspective, many of these platforms already have analytics for growth -- but the problem is they're across many platforms. I would like to see those analytics in one spot, and I also want historical data. Because I want historical data, I suspect we're going to need to take snapshots of the live metrics and save them somewhere.
Start Drawing!
I like to get drawing by this point. Check out this wicked design I did with my new toy:
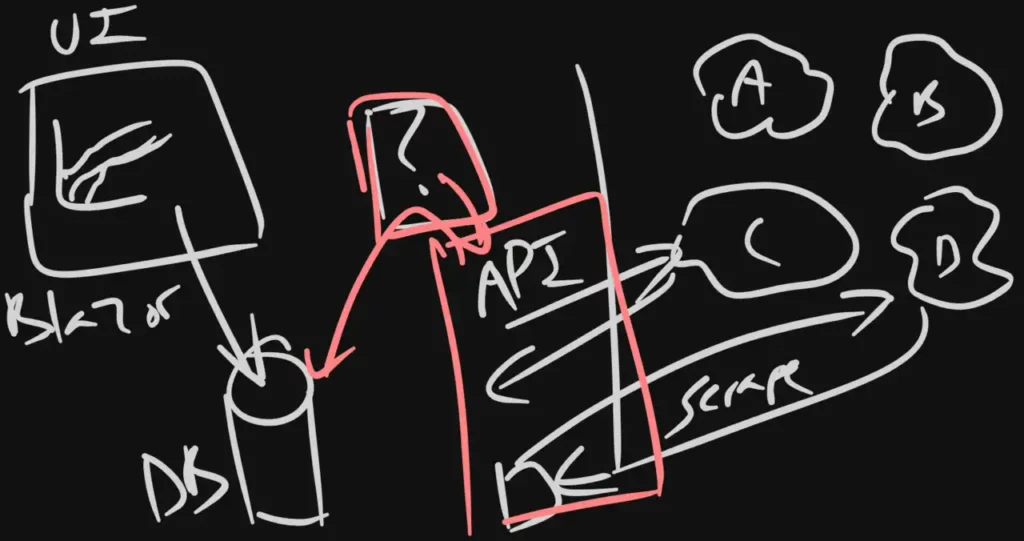
Okay... I draw like a 7 year old. But what we have:
- Blazor Web App in the top left
- Some database to persist our analytics (no tech chosen)
- A big question mark for "something" (probably a scheduler of some sort) that will talk to the APIs
- The API / scrapers we need to create and/or work with
- The different platforms out in their little "clouds"
We start very high level and we can decompose the problem space into smaller pieces.
Block Diagrams
My art masterpiece probably provided a little bit of a spoiler, but I like getting visual at this point. This is a personal preference as some people might do better writing notes and ideas down... but I need to visualize my thoughts.
I'm rationalizing that we'll have a few major components of our system... and when I say system, it's really just starting off nice and simple as a single Blazor app.
- The Blazor application
- The database where we want to store results
- ... the external systems we need to interact with to get metrics
- ... Something magic to glue this stuff together.
From other content I've posted online, you might know where my mind is going on this one:
Plugins.
We're going to build a plugin architecture at the core of this so we can get the extensibility I'm after. Plus, plugins are badass to begin with. So we'll want to get some blocks drawn out for plugins. Check out the next masterpiece here:
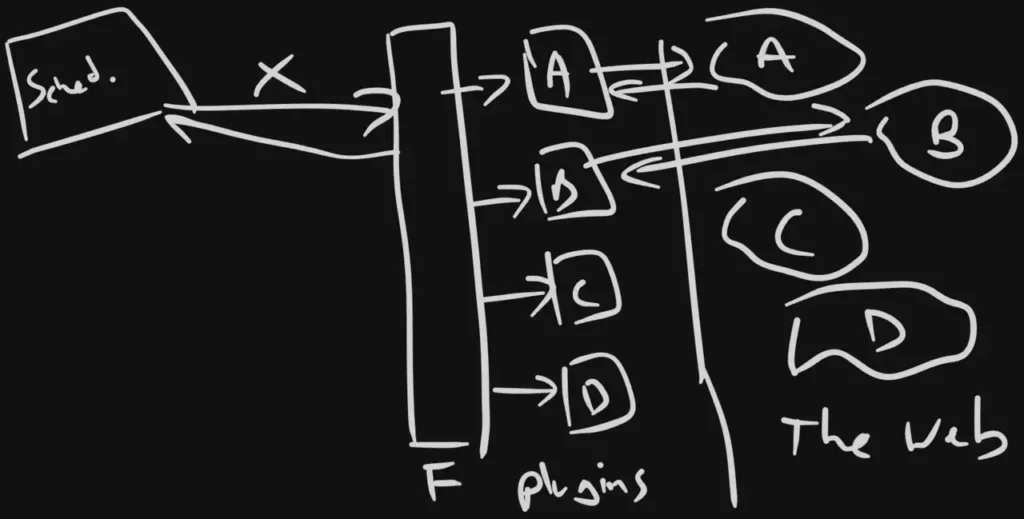
The F in the picture above is for a Facade design pattern. I like using these when I have a bunch of plugins to keep the system isolated from plugin implementations.
MVP
Meanest Veloci-Parrot. I have your attention now, right? Minimum Viable Product.
So that I don't go completely off the rails building every line of code as a plugin, we're going to discuss what the minimum set of features we need are for the MVP. This is critical when you're building REAL software for REAL customers because there's ALWAYS work to do. But this exercise forces you to think about what's the highest priority to get this in a customer's hands.
Fortunately for all of us: I am the customer here.
What I would like:
- Blazor web application that I can run locally on my computer
- 5 platforms supported for showing historical data for follower growth
- ... If that history starts NOW, that's okay.
- The UI doesn't need to do anything right now except indicate which data is for which platform.
- I want confidence that this can be extended to another platform with a simple code addition for that platform.
This means we don't need to worry about deployment. We have flexibility in which platforms we support. We don't need to build any fancy UI animations or special features.
We need some data from some platforms dropped into some database. I didn't even say what interval, so we can come up with something for that too. Customer Nick might change his mind later but that's all he asked for right now.
Moving Forward
Well the very next thing would be to watch this video, which should largely cover what we discussed here:
You could also check into getting early Discord Community access so that you can ask questions about this and help influence the direction we head in. Regardless of how, just remember that you can be involved and code along with this project. I'll publish a repo when the code starts flowing and potentially take pull requests.
Building real software is one of the best ways that we can improve as software engineers. These days I'm very busy with my own nutrition platform that I'm building -- but this will be a fun project that we can get put together!