
As software developers, it's inevitable that if we hang around long enough that we're going to encounter this. In fact, you've potentially faced this numerous times already--Dealing with legacy code. I know that just reading that probably made your stomach feel upset. I get it.
One of the big challenges when dealing with legacy code is fixing up bugs. Software engineers are incredible problem solvers though, so when faced with a challenging bug in legacy code, there's motivation to tackle something challenging. But the problem doesn't stop with the bug and the bug fix because it's all about what comes after. The tests.
In this article, I'll share with you my extremely simple strategy for making anything more testable. No more "It can't be tested" when dealing with legacy code. Instead, it should turn into "is it worth us testing". Let's go!
Note: This post is part of the 2023 .NET Advent Calendar! Check out the rest of the entries!
Remember to follow along!
Why Dealing With Legacy Code Is Challenging
Before I explain the strategy here, I think it's important to set the stage for why dealing with legacy code is challenging. It's a little bit more than just "I think the code is messy" or "it's totally spaghetti over there". This is *part* of it, but it doesn't fully explain it.
Legacy code, in general, moves against the few things we try to optimize for:
- Extensibility: Often the architecture was well suited for the time and as things evolve, it becomes less extensible. Adding new features becomes more challenging without having to refactor or retrofit aspects of it. It doesn't matter if you started off with clean architecture in .net core or hexagonal architecture for your ASP.NET application - whatever you picked just isn't lining up with the direction you need to move in.
- Low Coupling: Over time, more and more things eventually become coupled. It's always good to assume that the original developers did their best to reduce coupling, but over time more things sneak in. Without lots of time to refactor, these things can accumulate.
- High Cohesion: Same as the previous statement. Eventually without keeping up on tech debt, different modules of code can start to lose cohesion.
- Testability: One of the big ones for us in this article's focus is the testability. Given some of these other constraints, the testability is often low.
And not to mention that when we have all of these conditions working against us (and surely there are more not working in our favor), the odds are that we have low test coverage to begin with. This leads to a recipe of low confidence when making changes.
The Setup
Let's consider a system that we might have. I'll use the block diagrams below to illustrate:
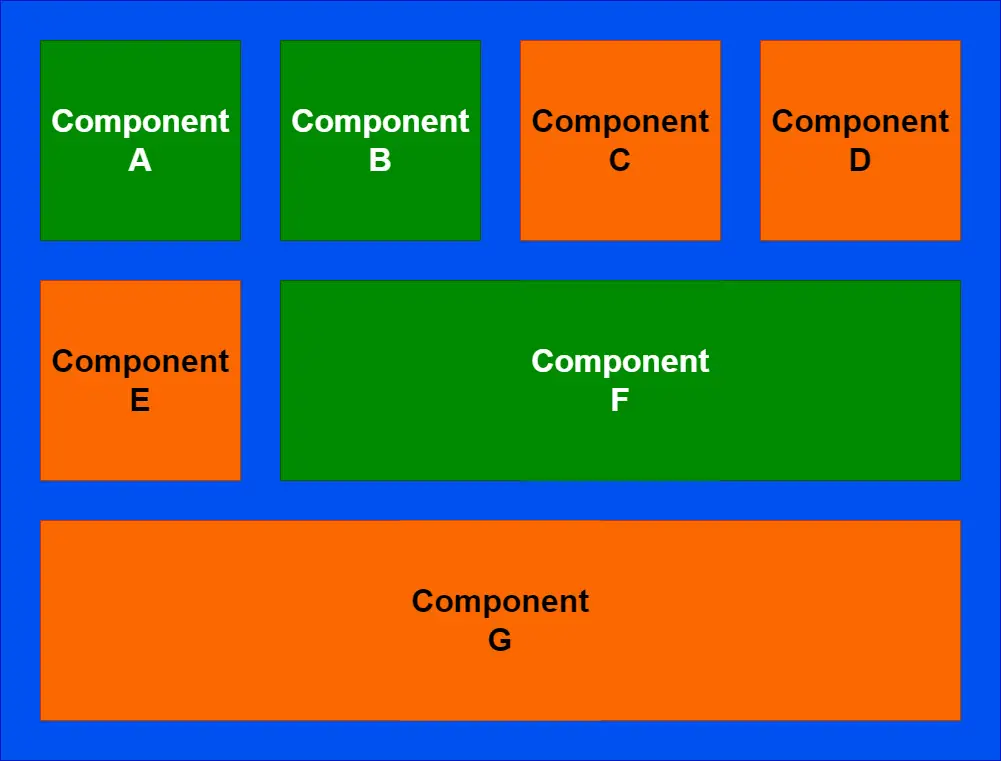
In the diagram above, let's assume that green components are ones that we have high confidence in when changing. This means that they're easier to navigate, easier to extend, have good test coverage... They're all (or most) of the things that we said legacy code isn't. We don't mind working in these areas. On the other hand, the orange components are the challenging ones to work with. "Legacy code" or not, they're low confidence when we're trying to deliver changes.
Let's consider that we have one component in particular, Component E, where we need to deliver a bug fix:
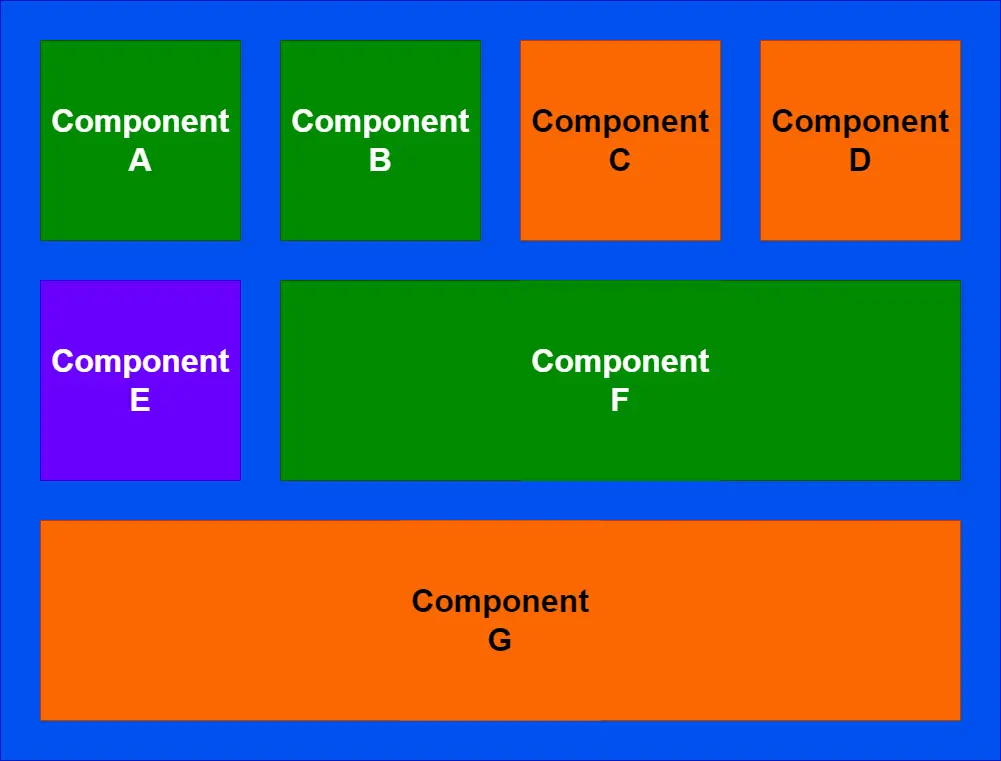
Component E here is where we've gone ahead and made our glorious bug fix! We're feeling accomplished because we spent hours debugging just to find a small bit of code buried in this legacy component that was busted. But we're now facing the situation of "So... where are the tests for this" and our usual response of "Well, it's in the legacy code... You KNOW that we can't test that...".
So let's change that.
The Paradigm Shift
The claim in these situations is that we can't test our logic because our logic exists in a spot that cannot be tested. And the more we try to rationalize this, the more we realize that we have a mountain of refactoring work on the legacy system to clean it all up, make it extensible, make it testable... you get it. It's going to take days, weeks, or MONTHS to get all of that in better shape. But this bug fix NEEDS to go out, and as much as that refactoring work and addressing tech debt would be nice... It's completely not a priority because this is the first bug fix in this area of code in years. (Feel free to come up with your own narrative and excuses here, I'm just trying to point out that as much as we'd love to go make all of this code pretty... ain't nobody got time for that).
So when we're dealing with legacy code in situations like this... Let's just accept it. We'll accept that we AREN'T going to go refactor this spaghetti mountain. Let's accept that it's going to be impossible to write nice clean tests over the system because it wasn't designed for it. Let's instead change our constraints that we're working with.
You touched some lines of code for your bug fix. If those lines of code weren't buried in the absolute depths of the legacy code, you could write tests over them. Surely! And no, these tests may not be your most ideal 100% end-to-end coverage and exercise every possible part of the system working together kind of test... But you said it COULDN'T be tested, and I'm here to say oh yes it can.
The Strategy for Dealing with Legacy Code
Our goal is to make it NET better for confidence, not chase perfection here. So if we want to add some amount of confidence for our change, all that we're going to do is extract the code that was altered into a new class and a new method. We'll minimize the foot print of anything else we touch.
That's it.
Literally, it's that simple. Instead of trying to make everything around your change more testable (because it's untestable), let's extract where you made adjustments to the logic and write tests specifically on that. Given that this is a bug fix in legacy code and we have VERY low confidence, we want to minimize our footprint for how much code we're touching. I'll explain more about the trade-off here in the next section. However, given our paradigm shift, we're looking for the minimum amount of code churn to add confidence on our changed logic.
- Extract method.
- Extract class.
- Instantiate it in the constructor of the spot you pulled it out of.
- Write the tests on the extracted code.
- Celebrate.
The Trade-Off
Before I walk through a code example, I just want to talk about the elephant in the room. And it's a big one, so hear me out.
Our Goal & Framing
The entire point of this approach is addressing a change that cannot have any type of test added around it. The goal was not to make the entire legacy part of the code base itself more testable--That surely requires refactoring and investment into tech debt.
Of course, if you have the time and capacity then you can work with your product owner to do that refactoring inline and then land the bug fix. There's nothing wrong with that, and in fact, it would be MY preferred way! But if we have the restrictions around:
- The code is too coupled to unwind easily
- We have to get this change shipped ASAP with more confidence
- This area of code is touched so infrequently that investing into a heavy refactor doesn't make sense
... Then this strategy can be excellent for you to prove more confidence. You can pair program or even sit down with a product owner to explain how your test passes/fails by reverting changes in the logic you extracted.
What We're Not Getting
Full end to end testing coverage isn't on the menu here. This means that this style of test that you're going to write to cover your extracted logic can be a harder sell to others. For example:
"Well, you extracted the code and how can you prove THAT doesn't cause a bug!"
... And you might not be able to easily. But that's why we were aiming to minimize our footprint. We want our change to be hyper focused on our bugfix + associated test(s). But that will mean that:
- Having more of a functional or integration test approach over the original code isn't in the picture
- Proving the end-to-end behavior that a customer might expect isn't illustrated in your tests
We're aiming for better than before, not perfect here. That's because of the constraints we mentioned.
A Million Little Pieces
So the good news is that the method(s) you pull out to cover with tests are likely adhering well to the single responsibility principle. The downside is that if you continue to repeat this over and over and over for your legacy code... You'll end up with a million little pieces.
If you're constantly going back to this code and having to do refactoring like this, you'll be slowly decoupling your code (yay!). However, if you are potentially narrowly-focused on this extraction process and not how to align and organize modules how you might given an opportunity to refactor. This means that your cohesion over time likely continues to plummet if you stay on this path.
Personally, my suggestion to you would be that if you have to do this more than a couple of times... You may want to have a conversation with your product owner about getting some time to refactor this code. It probably needs it and is worth the effort if you keep coming back to do this kind of approach.
Let's Try it Out!
Let's walk through an example that I have from my mealcoach.io nutrition platform.
Target Code
I'm going to jump to a random spot in this ASP.NET application and pick a part of a class to extract:
internal sealed class CognitoAuthenticationService
{
// hundreds of lines of code...
public Task<string> LoginAsync(
LoginParams loginParams,
CancellationToken ct)
{
// some code...
// where we have a bug!
var request = new AdminInitiateAuthRequest
{
UserPoolId = _cognitoConfig.UserPoolId,
ClientId = "big bad bug right here!",
AuthFlow = AuthFlowType.ADMIN_NO_SRP_AUTH
};
request.AuthParameters.Add("USERNAME", cognitoUsername);
request.AuthParameters.Add("PASSWORD", loginWithEmailAndPassword.Password);
// some code...
}
// hundreds of lines of code...
}We can see the bug clearly for the client ID being assigned the wrong value. But if we corrected this to pull the value from the Cognito configuration, how would we build confidence on the change?
internal sealed class CognitoAuthenticationService
{
// hundreds of lines of code...
public Task<string> LoginAsync(
LoginParams loginParams,
CancellationToken ct)
{
// some code...
// the code with the fix!
var request = new AdminInitiateAuthRequest
{
UserPoolId = _cognitoConfig.UserPoolId,
ClientId = _cognitoConfig.UserPoolClientId,
AuthFlow = AuthFlowType.ADMIN_NO_SRP_AUTH
};
request.AuthParameters.Add("USERNAME", cognitoUsername);
request.AuthParameters.Add("PASSWORD", loginWithEmailAndPassword.Password);
// some code...
}
// hundreds of lines of code...
}Follow Along!
You may find it easier to follow along with this video as well, which walks through this same concept on the same example:
Extract It!
Let's do exactly as we talked about and extract this code into a method, and then pull it into a new class:
internal sealed class CognitoRequestFactory
{
private readonly ICognitoConfig _cognitoConfig;
public CognitoRequestFactory(ICognitoConfig cognitoConfig)
{
_cognitoConfig = cognitoConfig;
}
public AdminInitiateAuthRequest CreateCognitoLoginRequest(
LoginWithEmailAndPassword loginWithEmailAndPassword,
string? cognitoUsername)
{
var request = new AdminInitiateAuthRequest
{
UserPoolId = _cognitoConfig.UserPoolId,
ClientId = _cognitoConfig.UserPoolClientId,
AuthFlow = AuthFlowType.ADMIN_NO_SRP_AUTH
};
request.AuthParameters.Add("USERNAME", cognitoUsername);
request.AuthParameters.Add("PASSWORD", loginWithEmailAndPassword.Password);
return request;
}
}Once extracted like this, we can see a couple of things:
- It's ridiculously easy to write tests on this now. We have a single method, a single dependency (that we could mock or not because it's a data transfer object but it also has an interface), and the logic is accessible to an external caller with nearly zero setup.
- We have a dependency that we need to pass in to this thing! But that's fine because the class that we pulled this out of had this same dependency passed into it
When you write tests on this method, you can even show your product owner or other colleagues the test failing initially (i.e. the code extracted without your fix) and then it passing (i.e. the code extracted WITH your fix). Again, this does not conclusively prove there are no bugs in your code. However, it does help add more confidence into your changes.
If you'd like to see another example of how to approach this, you can check out this video too!
Wrapping Up Dealing With Legacy Code
With the simple strategy we looked at, we can add at least SOME confidence when dealing with legacy code. The goal is not to aim for a perfect solution to making all of your legacy system more testable, but rather we're focused on making your change more testable.
There are certainly drawbacks to this approach--especially when we do this pattern on repeat. While it can be excellent for getting you out of a sticky situation where a fix needs to be delivered and more confidence would help, it may not be ideal to keep repeating. If you keep repeating it, then I'd suggest taking some additional time to ensure the pieces you're extracting are logically grouped. It might mean moving a bit slower and making a bit bigger footprint... but it might be best for the longevity of the code base.
Remember we can run into legacy code challenges regardless of which architecture we pick. It doesn't mean clean architecture in .net core, a C# plugin architecture, classic N-tier architecture in dotnet, or anything else is guaranteed to be a perfect solution for the lifetime of your app. Codebases that live long enough will have legacy code. If you're interested in more learning opportunities, subscribe to my free weekly newsletter and check out my YouTube channel!
Affiliations
These are products & services that I trust, use, and love. I get a kickback if you decide to use my links. There’s no pressure, but I only promote things that I like to use!
- BrandGhost: My social media content and scheduling tool that I use for ALL of my content!
- RackNerd: Cheap VPS hosting options that I love for low-resource usage!
- Contabo: Affordable VPS hosting options!
- ConvertKit: The platform I use for my newsletter!
- SparkLoop: Helps add value to my newsletter!
- Opus Clip: Tool for creating short-form videos!
- Newegg: For all sorts of computer components!
- Bulk Supplements: Huge selection of health supplements!
- Quora: I answer questions when folks request them!
Frequently Asked Questions: Dealing With Legacy Code
u003cstrongu003eWhat Are the Main Challenges of Dealing with Legacy Code?u003c/strongu003e
Legacy code often struggles with extensibility, high coupling, low cohesion, and poor testability. As software evolves, the architecture becomes less extensible, leading to difficulties in adding new features. Over time, more elements become coupled, and different modules lose cohesion. All these factors contribute to low test coverage and confidence when making changes.
What is the Basic Approach to Make Legacy Code More Testable?
The strategy to make legacy code more testable involves extracting the altered code into a new class and method, thus minimizing the impact on other parts of the code. This approach focuses on making the specific changes more testable rather than attempting to improve the testability of the entire legacy system.
How can Legacy Code Impact Software Development?
Working with legacy code often means dealing with parts of the system that are difficult to change or extend and have low test coverage. This creates a lack of confidence in delivering changes, especially in areas of the code considered challenging or "legacy".
What is this Paradigm Shift in Dealing with Legacy Code?
In dealing with legacy code, the paradigm shift is accepting that not all parts of the system can be tested or refactored easily. The focus shifts to writing tests for specific parts of the code that have been modified, even if it doesn't provide complete end-to-end coverage.
What are the Trade-Offs in this Strategy for Dealing with Legacy Code?
The strategy focuses on bettering the confidence in changes rather than achieving perfection. It involves extracting and testing specific logic changes but may not provide full end-to-end testing coverage. This can be a trade-off for achieving more immediate confidence in bug fixes or changes.
What Should Be Considered When Repeatedly Applying This Strategy to Legacy Code?
Repeated application of this strategy can lead to fragmentation of the code into many small, loosely connected pieces. It's essential to group extracted pieces logically and consider more substantial refactoring if the approach is used frequently.